
YOLO - You Only Look Once - Joseph Redmon et al.
Have you ever wondered how to locate Wally with Machine Learning?
The growing use of GPUs has allowed for the use of neural networks in image classification problems, this is, given an image and a set of categories, associating the image with the appropriate category. This type of solutions is the base for applications such as face recognition or self-driving cars. However, human sight is not limited to detecting the presence of a single object in an image, we are capable of locating several objects precisely in a single glance. This task is known as object detection and is far more complicated than image classification. Today, we’ll take a glance at YOLO. (The original paper introducing YOLO can be found here)
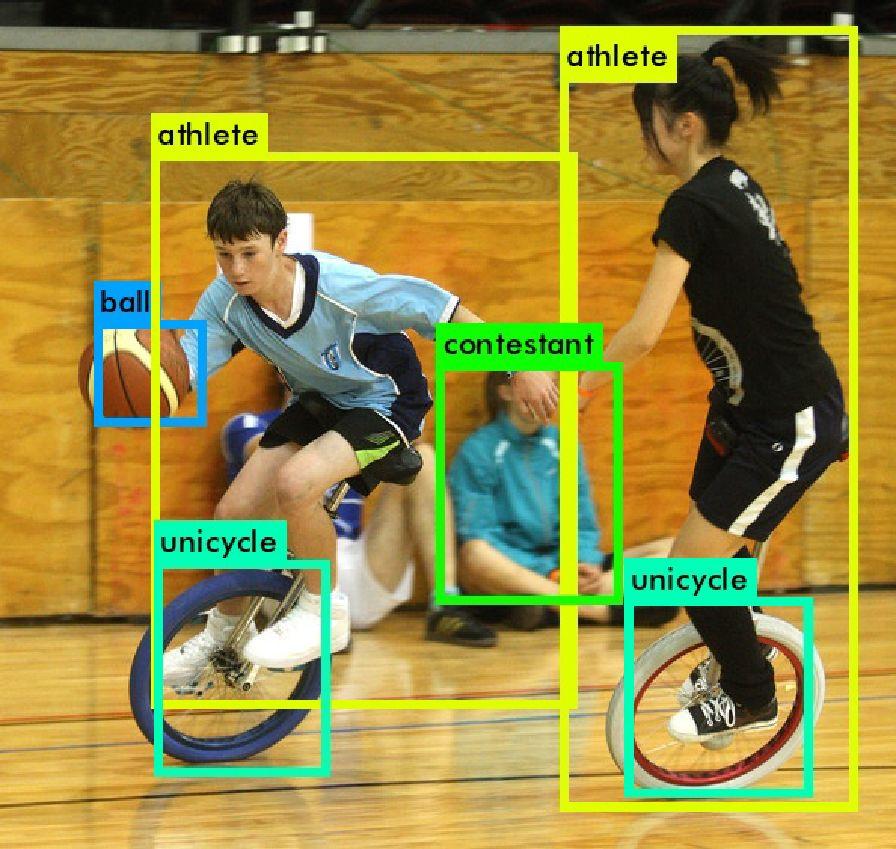
Images do not have to be common to be well detected by YOLO, they can be as random as a unicycle basketball competition.
Consider the problem of autonomous driving. We can use a wide range of sensors to help us decide what the car should do. The most important ones would provide us with visual information surrounding the car at each moment. Now the ball is in our court. We have all this data and need to solve the problem. We need to know if there are cars and how far, we need information about the pedestrians or obstacles that may cause us any trouble. And quickly. The latency between receiving the information and taking a decision should be minimal. In other words, we need to detect the objects present in the images received and be able to identify them to make a decision accordingly in real time.
In the past, the problem of object detection has been tackled reusing image classifiers. These classifiers would receive a region of the image as input and output the probabilities for each one of the possible classes. This approach is rather inefficient: to have precise regions overlapping images need to be fed through the network. Other methods, like [1], divide the task in two steps: selecting candidate regions and classifying the most likely regions to have an object. Although more efficient than the first approach, these systems are far from human sight, since we only need to process an image once to perform the task.
YOLO (You Only Look Once) [2] [3] [4] performs the task of object detection by processing the image only once, reducing the redundancy of the system. YOLO uses a convolutional neural network to generate precisely the bounding boxes that enclose the objects (up to 9000 object types in YOLO9000) present in the image. Besides being precise, YOLO is blazing fast in comparison to previous systems [3] and can perform real-time object detection (as can be seen HERE). Being able to perform real-time predictions is a requirement for the use of image object detection in systems such as autonomous driving, where their usability doesn’t only depend on their precision but also on the latency of the response.
Architecture details
The base version of YOLO uses a neural network for prediction composed of 24 convolutional layers and 2 dense layers. There is an obvious trade-off between the speed and accuracy of the predicting neural network used. Due to this, an even faster version, Fast YOLO, was developed reducing the complexity of the network.
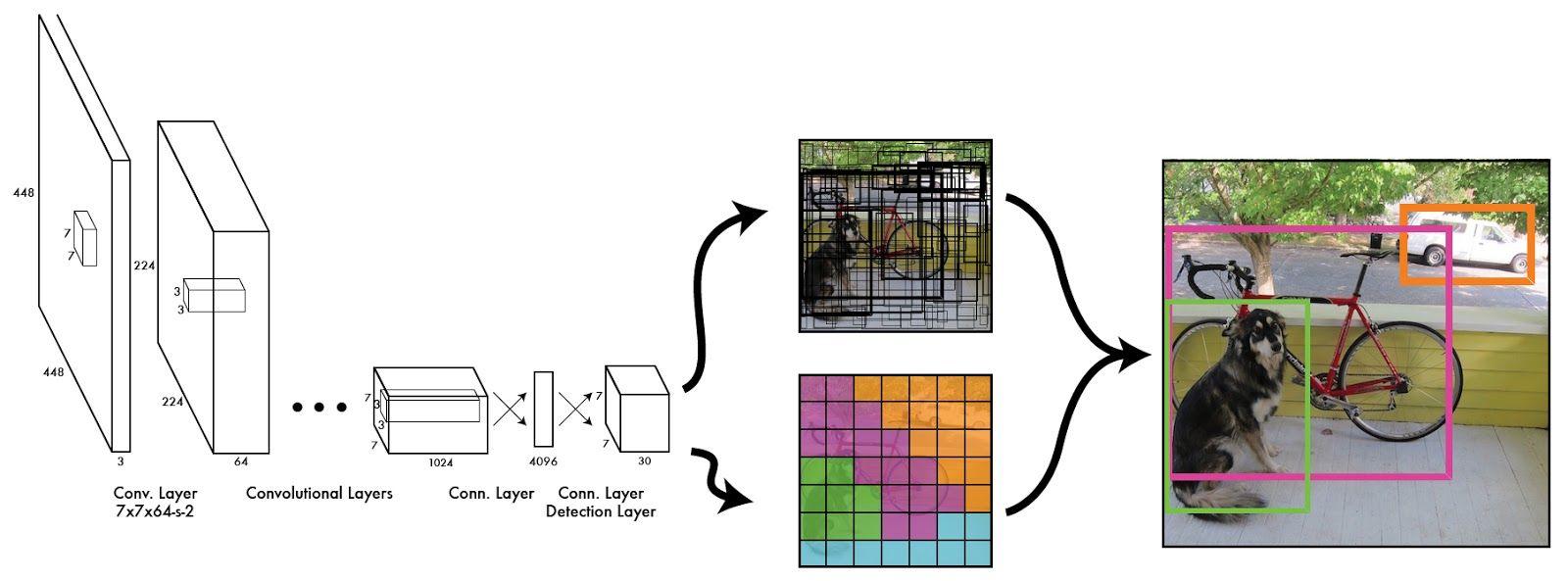
YOLO resizes each input image to 448x448. Then, it divides the image into an SxS grid. Each one of these cells predicts B bounding boxes, the location given by x, y, height, width and the confidence of an object being present in the box. Additionally, each grid cell also outputs the probability Pc of containing each one of the C classes the system was trained on. The final probability of finding an object Ci in each bounding box is found multiplying the confidence of the bounding box by Pc.
YOLO, and its successive versions, perform like state-of-the-art detectors such as Fast R-CNN in the PASCAL VOC2012 and COCO datasets, using the shortest predictions times. YOLO has also proven to learn general representations of objects. For example, it has been shown to work well with artwork datasets, such as Picasso and People-Art datasets, that differ largely at pixel level from natural images.

YOLOv2 [3] and YOLOv3 [4] propose tweaks over the base version of YOLO that improve the overall accuracy of the system. Some of these improvements include:
- A different way of predicting the bounding boxes, known as anchor boxes, simplifies their prediction and makes it easier to learn.
- A more complex neural network inspired in the latest studies in image detection, such as batch normalization and residual networks.
- The ability to predict on images of different sizes which offers a trade-off between speed and accuracy.
Moreover, the YOLO9000 architecture can be trained both on object detection and classification, which allows it to use the great variety in object types in image classification datasets (up to 9000 class types in ImageNet) for the task of object detection.
Not too bad, huh?

How to use YOLO
YOLO is implemented using the Darknet framework, an open source neural network framework written in C and CUDA. The latest weights for the system (YOLOv3) are available to download online.
To install the framework we can simply run:
git clone https://github.com/pjreddie/darknet
cd darknet
make
The latest weights can be downloaded:
wget https://pjreddie.com/media/files/yolov3.weights
Finally, to predict the output for an image (in this case waldo_vs_odlaw.jpg) we can run:
./darknet detect cfg/yolov3.cfg yolov3.weights data/waldo_vs_odlaw.jpg

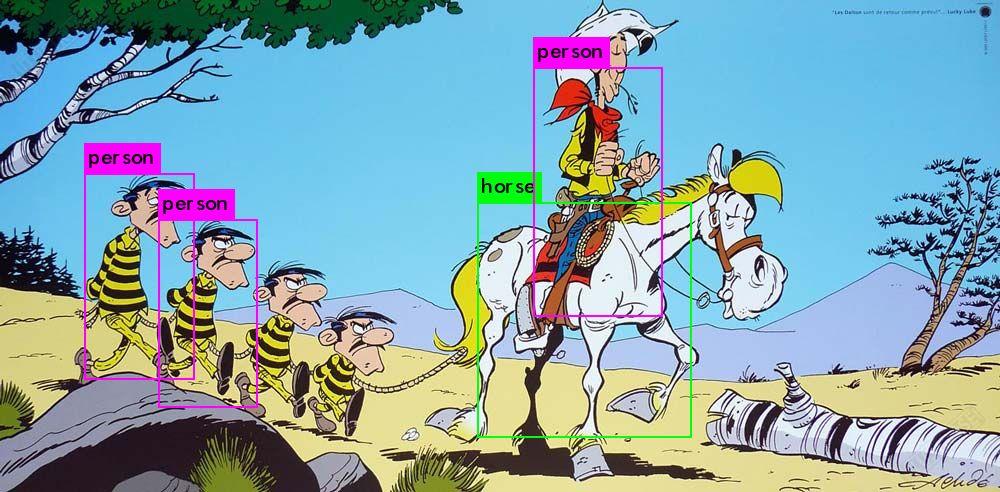
OH! It looks like Waldo and his Dalton-looking arch-nemesis Odlaw are the same person! Talking about the Daltons… it seems that only two of them seem to be actual people.
Conclusion
Image Object Detection is a more complex problem than Image Classification as it requires the segmentation of a single image into regions. Most state-of-the-art systems approach the task in two steps: dividing the image in candidate regions and then classifying these regions with an image classifier. YOLO proposes a faster approach for the problem, solving the task by processing the image only once, closer to what human vision does. This is a big step in the development of real time vision systems that could be incorporated to robotics applications or even self-driving cars since both rely on predictions with low latency.
For further information on the details of YOLO, watch the Joseph Redmon’s TED talk or visit its website.
References
[1] R. B. Girshick. Fast R-CNN. CoRR, abs/1504.08083, 2015. [https://arxiv.org/abs/1504.08083]
[2] Joseph Redmon, Santosh Divvala, Ross Girshick, Ali Farhadi. You Only Look Once: Unified, Real-Time Object Detection, 2016. [https://pjreddie.com/media/files/papers/yolo.pdf]
[3] Joseph Redmon, Ali Farhadi. YOLO9000: Better, Faster, Stronger, 2016. [https://arxiv.org/abs/1612.08242]
[4] Joseph Redmon, Ali Farhadi. YOLOv3: An Incremental Improvement. [https://pjreddie.com/media/files/papers/YOLOv3.pdf] [5] Kaiming He, Xiangyu Zhang, Shaoqing Ren, Jian Sun. Deep Residual Learning for Image Recognition. 2015. [https://arxiv.org/abs/1512.03385]