
Not reinventing the wheel I - MapReduce
This is the first of a series of posts on BigData software and architecture. The main goal of this series is to not reinvent the wheel by re-developing a system that is already out there. A more intelligent approach always takes into account the existing tools and either re-uses them or builds on top of them if necessary. In the unlikely case that your personal/company’s problem is different to anything out there already and you believe you need to develop it from scratch, it will always help to know which problems you will have to face in the near future.
The original paper introducing MapReduce can be found here.
MapReduce is a functional programming model where users specify a Map and a Reduce functions to process a dataset. In 2003, Google took inspiration of this model and implemented a scalable abstraction that executes the map and reduce tasks on a cluster. This abstraction avoids the necessity of duplicating code across all the implementations that are mappable to this model and allows for the automatic parallelization of the tasks when executed in a cluster. This parallelization is supported by a large set of features that include task scheduling, load balancing, fault tolerance (common in clusters with a large number of machines) and inter-machine communication.
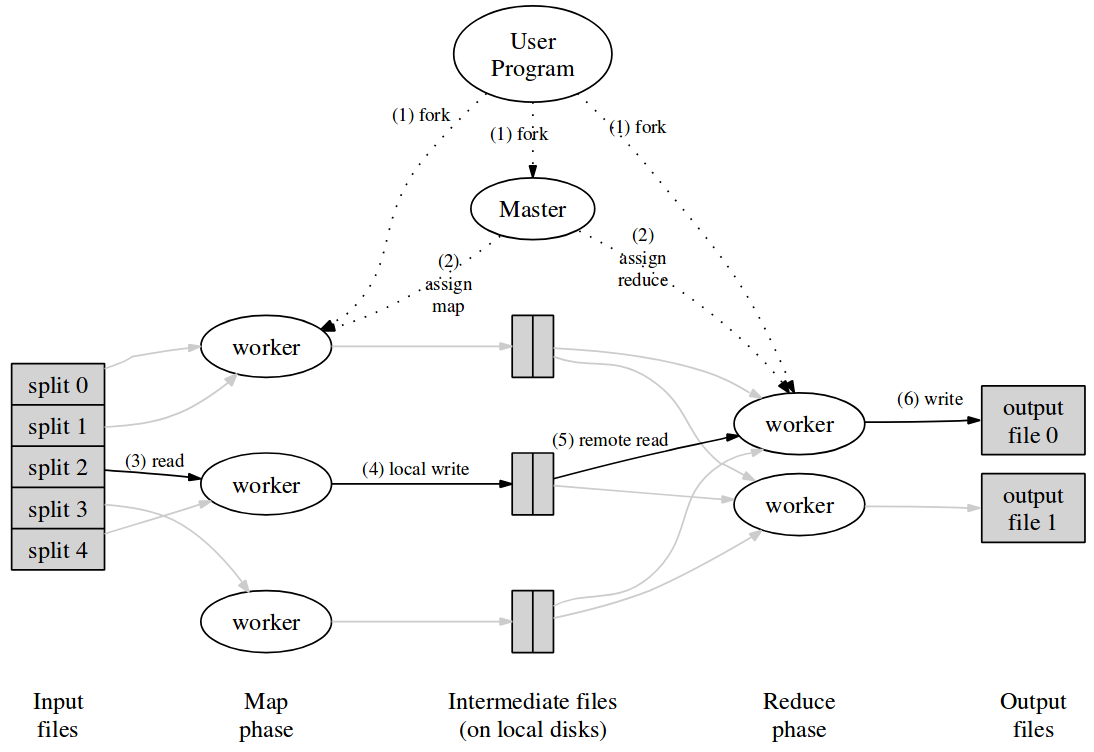
The execution is divided in the Map and Reduce phases. The input to the Map tasks, a function implemented by the user, is a set of input key/value pairs (e.g. base URL and website content) and produces an intermediate set of key/value pairs (e.g. URL mentioned in the website and the base URL). All the pairs with the same key are put together and a Reduce function is executed. The reduce function, consequently, receives a single key and its set of values (e.g URL mentioned and a list of URLs that mention it) and produces a key/value pair out of it (e.g. URL mentioned and number of times that it is mentioned). Once every reduce task has been completed, the user program resumes its execution.
When using MapReduce, M splits of the input data are generated (chunks of 16-64 mB). These splits can be assigned to different machines that will execute the map task in parallel. Following this execution, the intermediate keys (output of the Map executions) are split into R pieces, making sure to group together in one machine the outputs with the same key. This is done through the implementation of a partitioning function that can be defined by the user (e.g. hash(key) mod R). For some tasks, the intermediate keys can also be aggregated locally before being partitioned to speed up the execution.
Each one of the machines that executes map or reduce task is called a worker. An additional machine, called master, is in charge of the scheduling of tasks to idle workers. The intermediate pairs generated from executing a map task are eventually copied to the machine’s local disk (and duplicated in at least two other workers) and the locations are sent to master. Master tries to schedule the workers in a way that takes advantage of this locality to reduce the network’s usage. However, if a worker needs to read from a different machine it does so using the distributed file system GFS. During the execution of these tasks, workers are periodically pinged by master, ensuring that the execution has not failed or that the machine is down. If this is the case, the corresponding task is reassigned to another worker. This same approach is taken for workers that are taking too long to complete a task (stragglers). Master also writes checkpoints to guarantee that if it is the master node the one failing, a new copy can be started from that point without losing complete progress.
Generally speaking, the use of MapReduce provides users without experience in distributed systems to enjoy the seamless parallelization of their code in a cluster infrastructure along with a set of refinements. These refinements do not only speed up the execution but also have built-in mechanisms to deal with machine failures. Consequently, the use of MapReduce leads to simpler code implementations of really complex tasks, like Google’s Reverse Web-Link Graph, which would be otherwise hard to implement reliably.